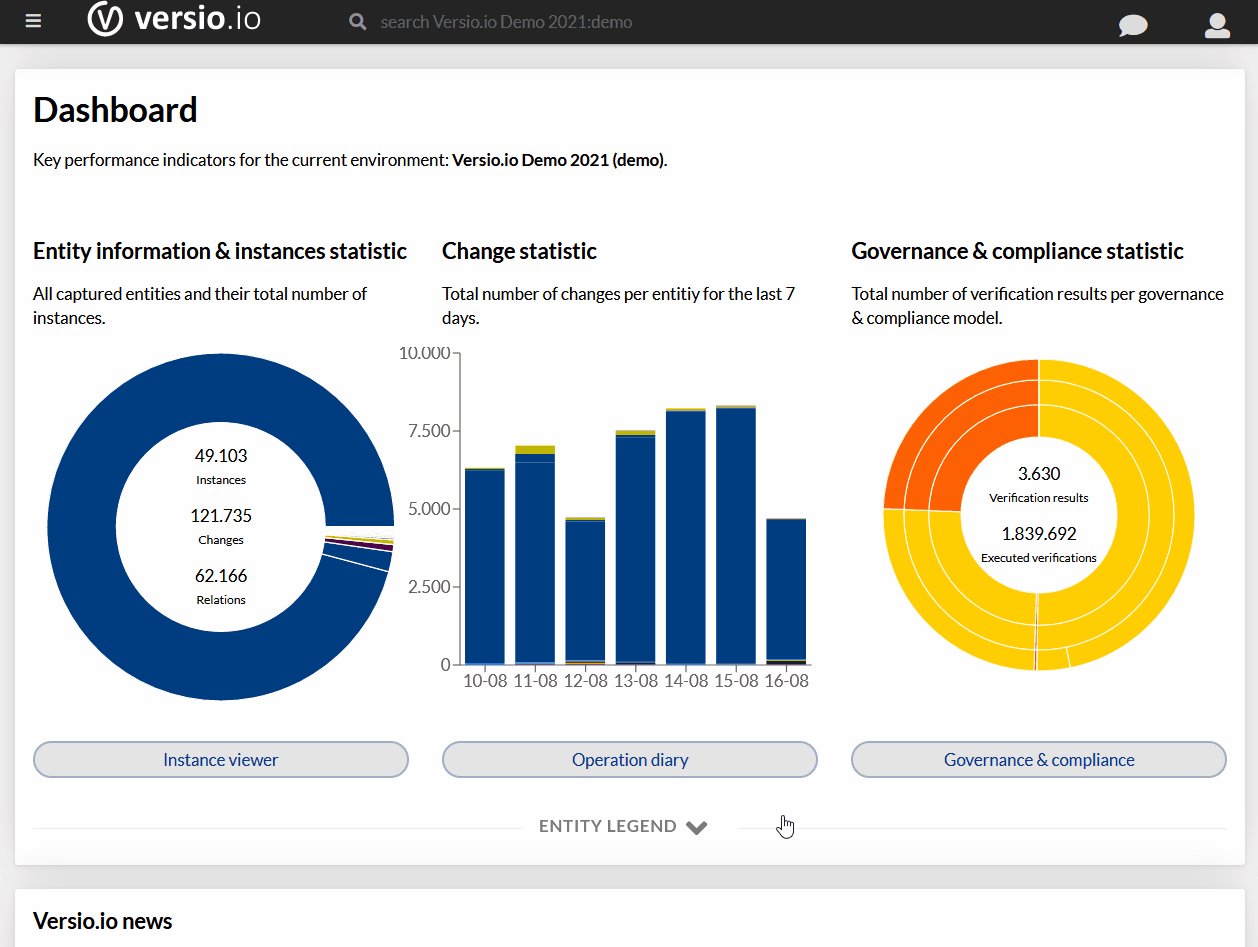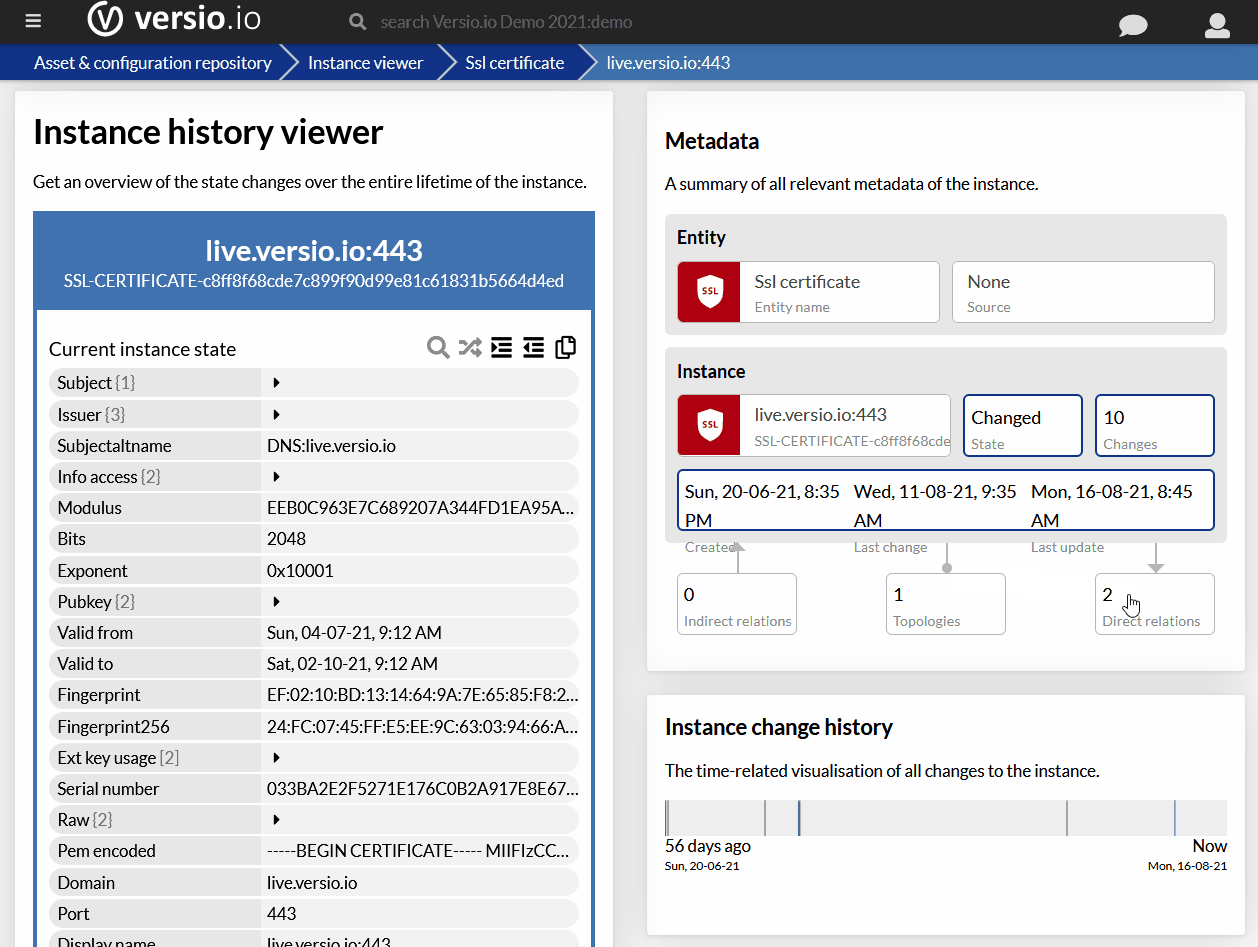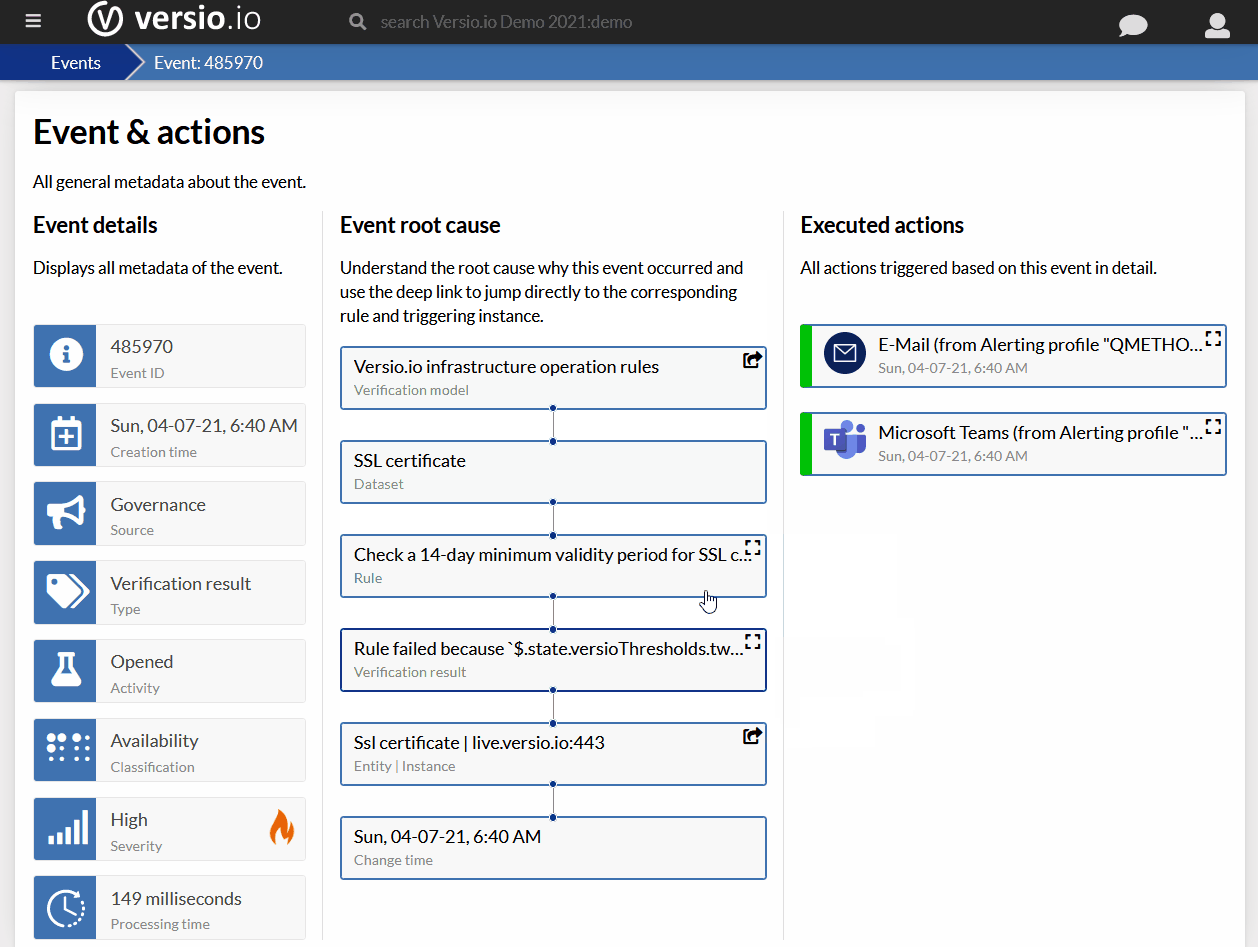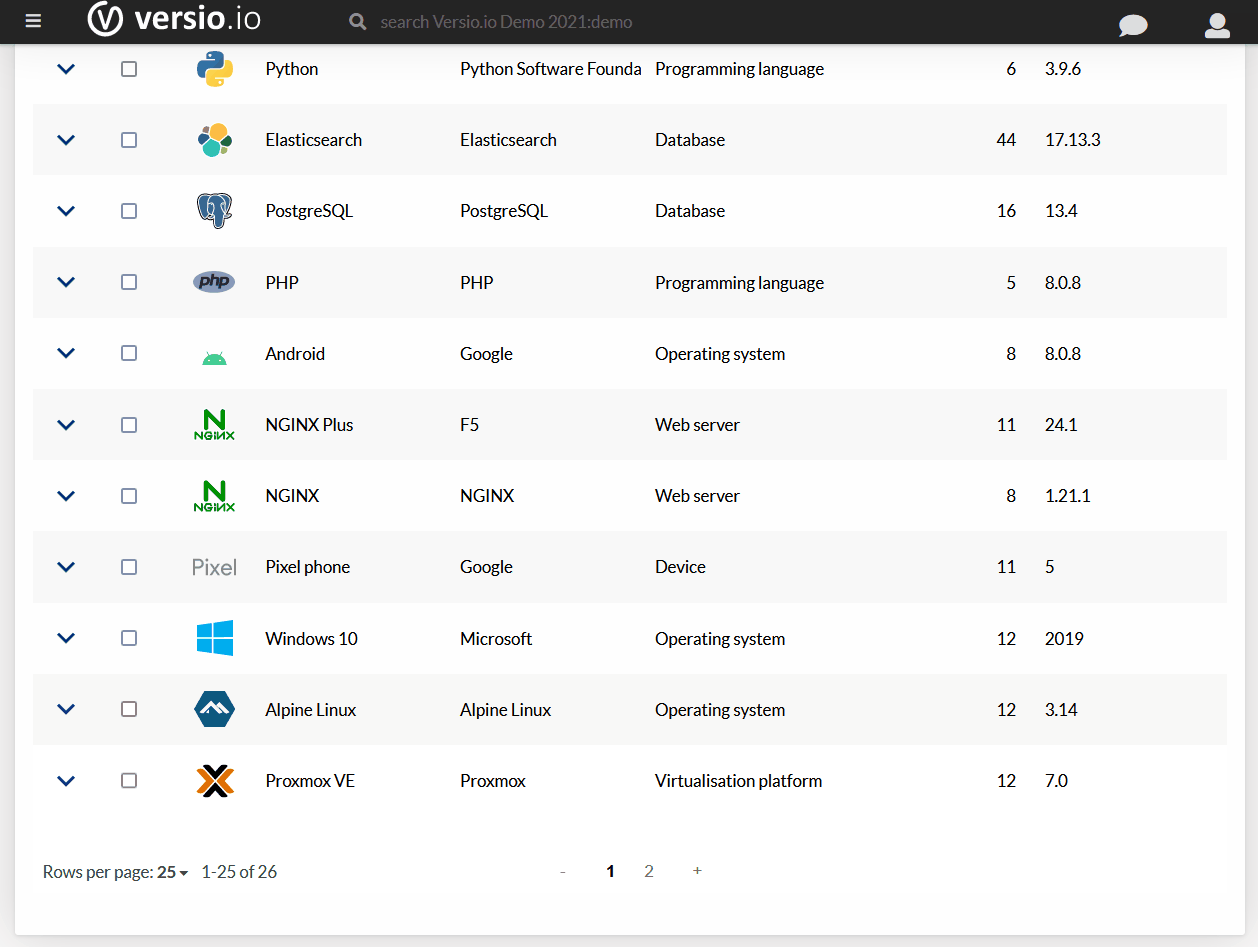
Po instalacji Elasticsearcha, opisanej w części 1, naszła mnie wątpliwość. Bo co tam w końcu się zainstalowało, o ile poszło bez problemów? I po co to wszystko?
O Elasticsearch mówi się, że to full text search engine zbudowany na bazie Apache Lucene, czyli open-source’owej maszyny indeksująco-wyszukującej. Lucynka dużo może, dlatego dobrze pasuje do wielkiej ilości danych, czyli Big Data. A to w dobie Internet of Things (IoT) zaczyna mieć znaczenie i dlatego firma Elastic postanowiła wykorzystać Lucynę jako bazę swoich rozwiązań.
Elasticsearch jest silnikiem działającym w czasie niemal rzeczywistym (performance), dobrze się skaluje (big data, big deployments) oraz jest redundantny i podobno dzięki temu odporny na awarie (fault tolerance). A do tego świetnie się integruje poprzez swoje API dostępne w wielu językach (Java, PHP, Ruby, Python, .NET i Google wie, co jeszcze). Koncepcja architektoniczna ELKa jest zbliżona do mikroserwisów, które działają niezależnie, ale można je łatwo ze sobą łączyć w większe jednostki, budując z nich niezawodne rozwiązania, niezależne od wybranej technologii implementacyjnej.
Ludzie gadają, że nie trzeba być konstruktorem czy mechanikiem, żeby jeździć samochodem. Pytanie tylko, jak długo i dobrze? Jak dobry kierowca rozumie, jak działają różne mechanizmy i systemy w aucie, to dobry developer powinien rozumieć, jaka jest architektura i działanie komponentów i frameworków, na których buduje swoje rozwiązania. Tak to mniej więcej wygląda (w pigułce):
- Node (węzeł, instancja) — pojedynczy serwer Elasticsearcha, który indeksuje, przechowuje i wyszukuje dane. Node może być dowolnie nazwany, choć w większości developerskich instalacji zostają nazwy domyślne, nadawane podczas instalacji.
- Cluster — grupa logicznie powiązanych węzłów (nodes). Działa jak klastry w innych rozwiązaniach, gdzie węzły wykonują rozdzieloną między nie robotę na rzecz klastra, do którego należą. Klastry identyfikowane są po nazwie. Domyślna nazwa klastra nadawana podczas instalacji to elasticsearch.
- Index — zbiór dokumentów, które są podstawową jednostką indeksowania. Do indeksu należą dokumenty o podobnych parametrach. Przykładowo, do jednego indeksu powinny należeć dokumenty opisujące np. klienta, a do innego dokumenty opisujące produkty.
- Document — podstawowa jednostka indeksowania. Dokumentem może być plik opisujący jednego klienta, albo jeden produkt, albo jedno zamówienie. Elasticsearch tworzy dokumenty w formacie JSON (JavaScript Object Notation).
- Type — jeden indeks może zawierać wiele typów. I bynajmniej nie chodzi o typy spod ciemnej gwiazdy. Typ powinien charakteryzować dokumenty o jednakowych polach. Przykładowo, w jednym indeksie dotyczącym produktów, można wyróżnić produkty typu „sprzedawany lokalnie”, albo typu „wycofany ze sprzedaży” itd.
- Shard/Replica — jest to pojęcie ściśle związane ze skalowalnością i redundancją Lucynki, a co za tym idzie, również i Elasticsearcha. Shard (jak ci się rozbije lustro albo szklanka, to masz stłukle, czyli shards) jest związany ze skalowalnością i może zostać stworzony podczas tworzenia indeksu. Stłukli może być wiele i są one funkcjonalnymi i niezależnymi indeksami (w sensie indeksów Lucene) rezydującymi na dowolnym węźle klastra. Sharding pozwala na rozłożenie obciążenia indeksowaniem na wiele węzłów, a właściwa konfiguracja pozwala na zwiększenie wydajności systemu.
Pojedynczy shard może pomieścić integer128 dokumentów, czyli jakieś 2 miliardy z drobnym hakiem. Pamiętaj o tym, bo więcej dokumentów nie da się Lucynie wcisnąć.
Repliki służą do tworzenia kopii shardów na różnych serwerach, co zapewnia redundancję instalacji i nieprzerwane jej działanie w razie awarii któregokolwiek z nich. Domyślnie, Elasticsearch tworzy 5 shardów głównych (primary) na indeks oraz jedną replikę. Czyli, w przypadku dwóch węzłów, każdy z nich będzie miał 5 primary shards i 5 replik, bo każdy primary shard ma jedną replikę. Normalnie, puszka Pandory, ale potem wystarczy zbyt często tam nie zaglądać i da się przeżyć. A jak ktoś sie nie boi i lubi poeksperymentować, to później wyjaśnię, jak właściwie to skonfigurować, żeby osiągnąć jak najwyższą wydajność.
Ja mam już dość, bo trochę czasu zajęło mi zrozumienie, dlaczego architektura Elasticsearcha właśnie tak wygląda. Ale jak już się z tym prześpisz i zrozumiesz, wszystko okaże się logiczne i uzasadnione. Bo jako Omnibus, nie tylko będziesz zmuszony do korzystania z ELK, ale jeszcze będziesz musiał się znać na wdrożeniach i optymalizacji wydajności. Ale dojdziemy i do tego, ciąg dalszy nastąpi w części 3.