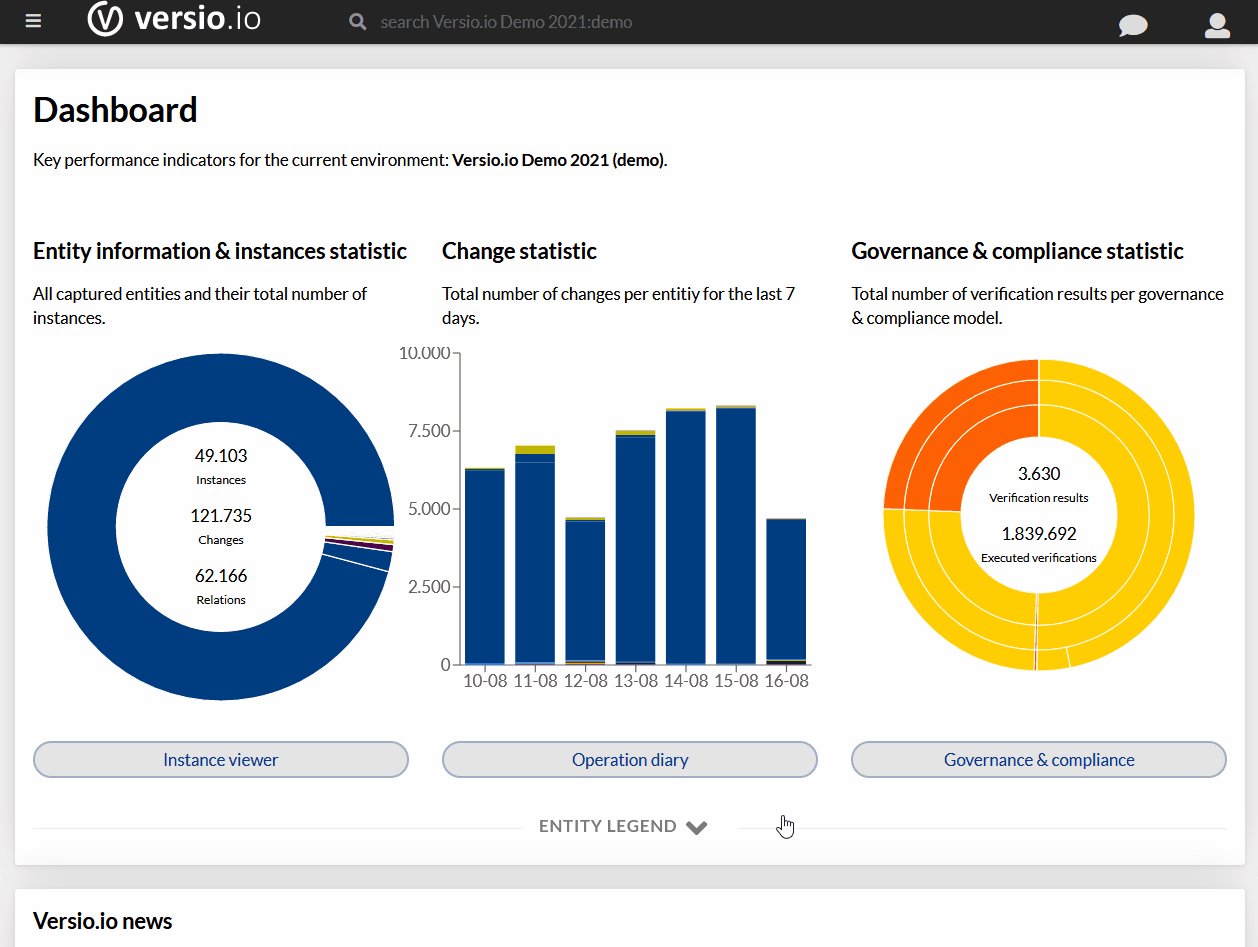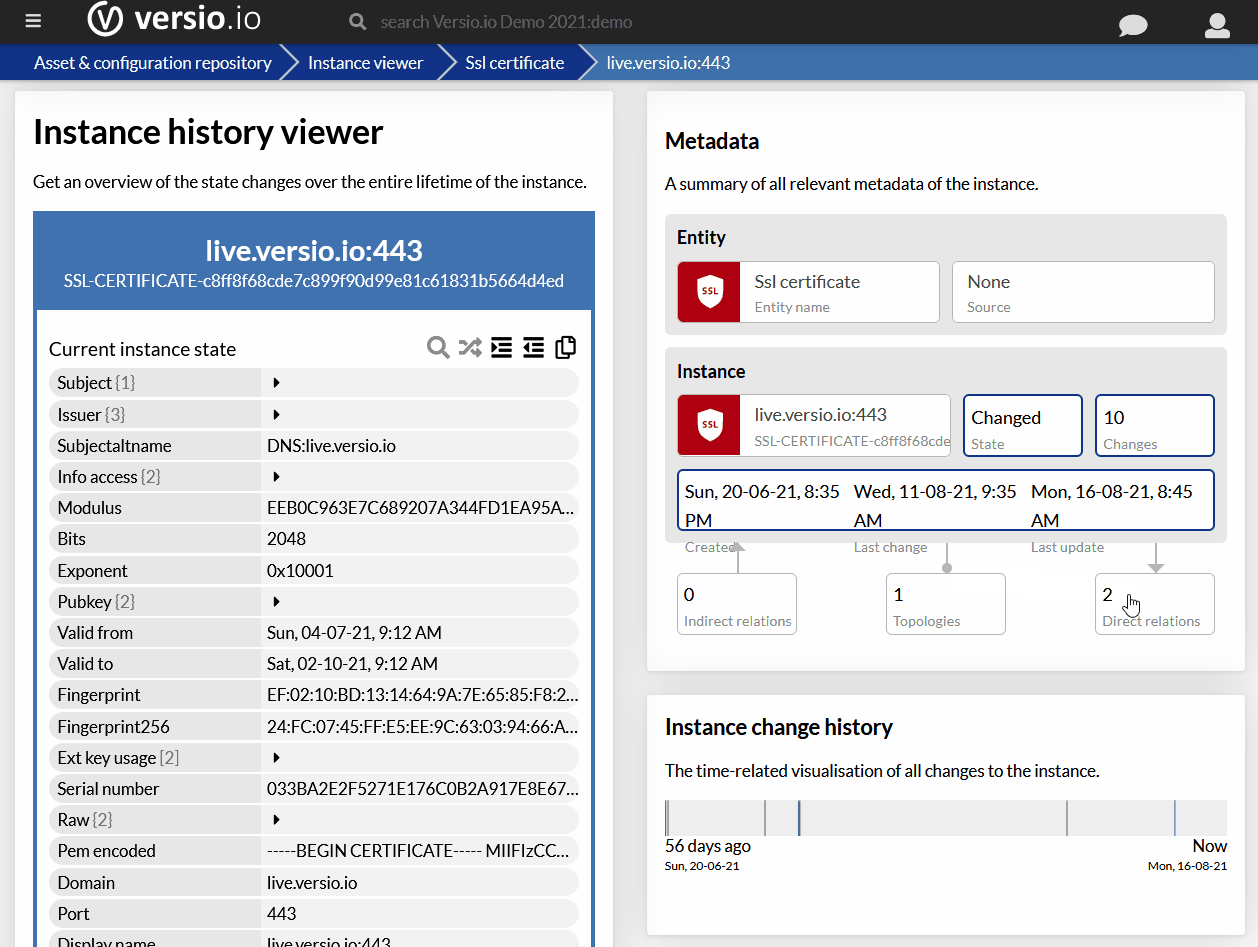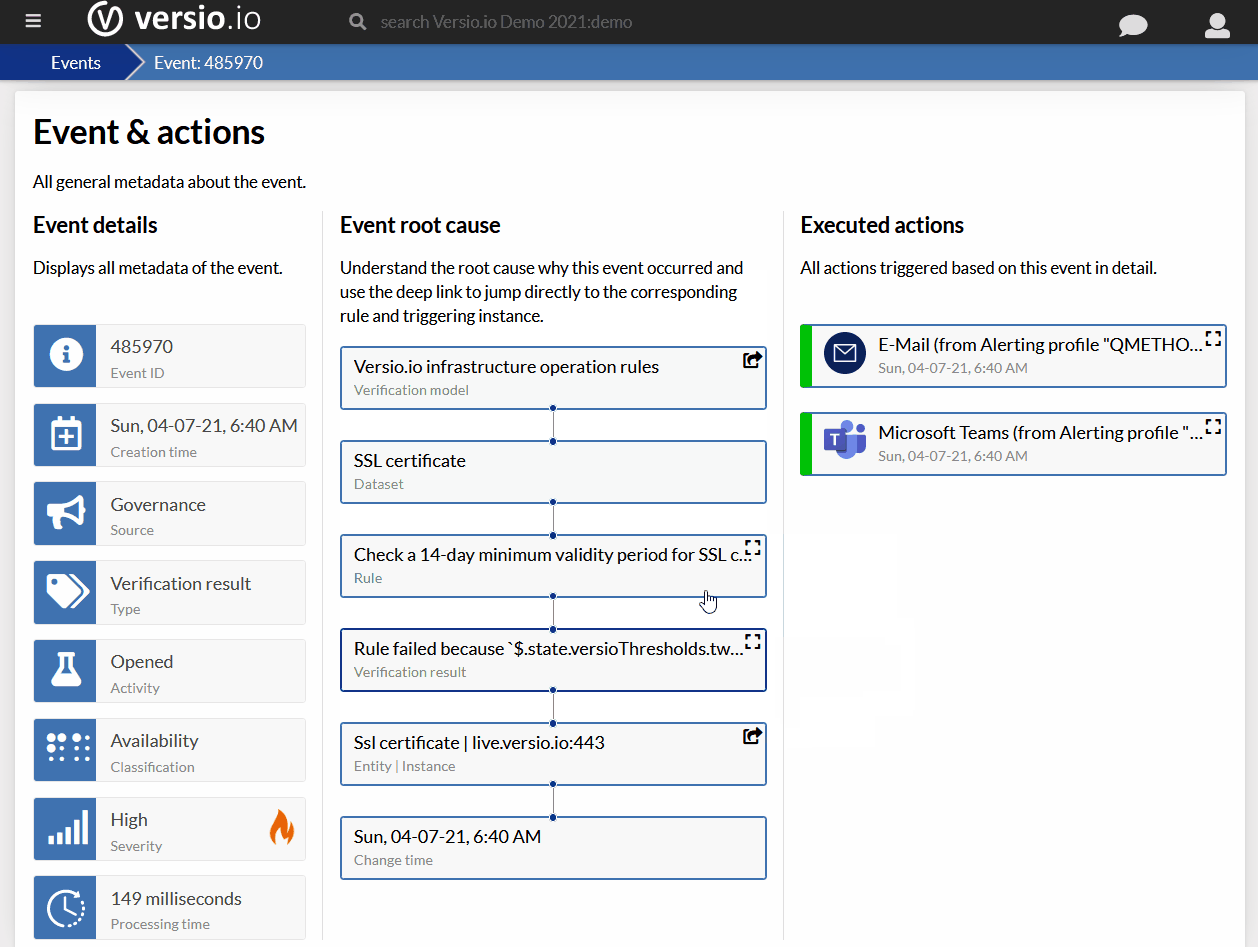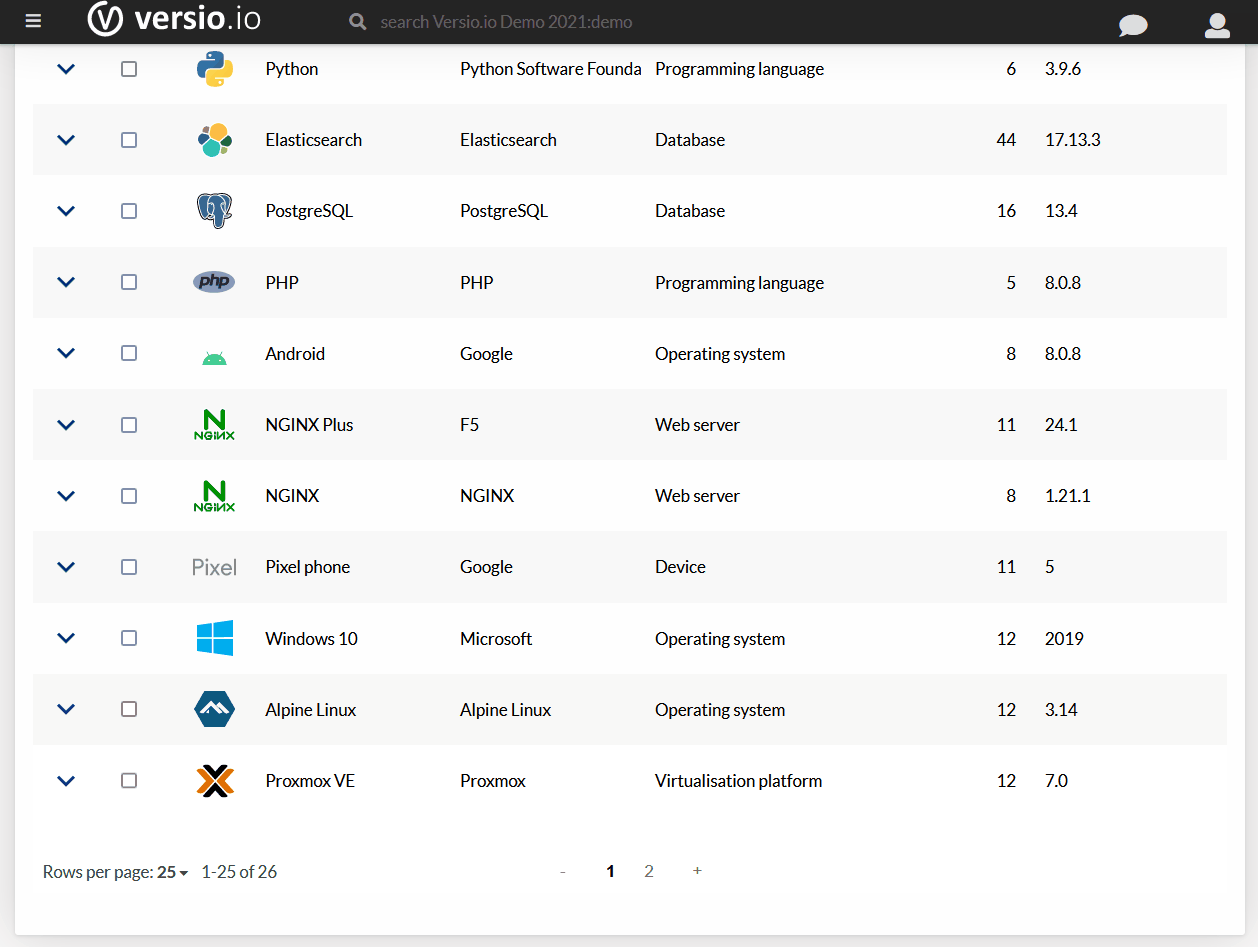
Zapewnienie dostępności i prawidłowego działania aplikacji jest głównym zadaniem zespołów utrzymania aplikacji. Kluczowa jest w tym skuteczna komunikacja z innymi zespołami: developerami i managementem. Dodając do tego współpracę z zewnętrznymi poddostawcami tworzy się problem jasnego określania skuteczności – czy nasze aplikacje są dostępne i jak spisują się poszczególne usługi, za które odpowiedzialne są konkretne zespoły. Potrzebne są wskaźniki zrozumiałe dla wszystkich w organizacji, których dynamikę możemy obserwować i wskazywać obszary do poprawy, wyciągać wnioski ze współpracy. Z pomocą przychodzi opracowana przez Google metodologia SRE – Site Reliability Engineering. Wprowadza ona pojęcie Service-Level Objective (SLO) – wymiernego celu poziomu zapewnienia usług określanego na podstawie kluczowych wskaźników poziomu usług Service-Level Indicators (SLI), którymi są konkretne metryki z naszego systemu monitoringu. Na ich podstawie ustalone mogę zostać zarówno wewnętrzne jak i zewnętrzne umowy poziomu usług Service-Level Agreement (SLA), które tworzą zobowiązanie pomiędzy dostawcami a klientem i wskazują na konsekwencje ich niespełnienia.

Różnica pomiędzy aktualną wartością SLO a zakładanym celem jest naszym budżetem błędu (Error budget), pozostałym buforem niezawodności usług. Jak wygląda praktyczna implementacja SRE dla przykładowej aplikacji? Sprawdźmy to dla platformy Dynatrace.
Na początek należy zastanowić się, jakie czynniki i w jakich obszarach naszej aplikacji będą podlegały ocenie. Możemy wyjść od oczekiwań klientów, którzy chcą, aby aplikacje były po pierwsze zawsze dostępne, a po drugie działały poprawnie i szybko. Jak to zmierzyć? Niezastąpiony okazuje się Real User Monitoring – rejestrowanie przez Dynatrace sesji użytkowników po stronie ich urządzeń końcowych, które przekłada się na znajomość czasów ładowania, poziomu ilości błędów i docelowo poziomu zadowolenia z podziałem na poszczególne akcje, funkcjonalność aplikacji. Samą dostępność zmierzymy wykorzystując Synthetic monitoring – okresowo wykonywane odpytania strony czy zasymulowanie krytycznej ścieżki użytkownika w przeglądarce wskazujące 24/7 aktywność z wybranych lokalizacji na świecie. Interesująca powinna być również strona serwerowa przetwarzania – wydajność kluczowych usług oraz wysycenie zasobów. Do tego zestawu możemy dodać dowolną metrykę, której określony poziom jesteśmy świadomi, że świadczy o pożądanym czy nie pożądanym działaniu aplikacji. Najważniejsze, aby wartości były dokładne, prawdziwe oraz zbierane z odpowiednią częstotliwością. Tutaj warto też rozważyć rodzaj agregacji, czy opieramy się na średniej wartości z określonego okresu czy może maksimum, minimum albo innej dostępnej.
Kolejnym krokiem jest określenie celu, jaki chcemy osiągnąć dla każdej z metryk. Najprostszym przypadkiem jest dostępność, czyli oczekujemy, że nasza aplikacja będzie widoczna zawsze, przez blisko 100% czasu. W rzeczywistości to wynik trudny do osiągnięcia, wliczając okna serwisowe czy chwilowe możliwe problemy zakładamy np. 99,9%, dokładając kolejny 9 po przecinku chcąc jeszcze podwyższyć wymagania. Kolejno chcielibyśmy, aby 100% użytkowników korzystających z naszej aplikacji było z niej zadowolonych. Możemy oprzeć się o wskaźnik APDEX, który bierze pod uwagę czasy ładowania, błędy czy awarie występujące na stronie oraz zachowania wskazujące na frustrację (rage clicks). Jest on mierzony standardowo przez Dynatrace dla całej aplikacji oraz oddzielnie dla poszczególnych akcji użytkowników. Warto spojrzeć na jego historyczne wartości, szczególnie dla dni, z których działania aplikacji jesteśmy zadowoleni i tam ustawić poprzeczkę. Podobnie dla wydajności usług – określamy czas odpowiedzi zapytań, który byłby wskazany, aby nie wpływał negatywnie na odczucia użytkowników. W przypadku przekroczenia tych poziomów wykorzystamy dostępne w Dynatrace narzędzia do analizy przyczyn i zrozumienia „wąskich gardeł”, na których należy skupić się w optymalizacji. Cele powinny być osiągalne i łatwe do zrozumienia dla wszystkich. Najważniejszy będzie obserwowany z okresu na okres trend, czy radzimy sobie coraz lepiej i optymalizujemy aplikację. Ułatwia to współpracę z naszymi dostawcami oraz wewnętrznymi zespołami utrzymania i rozwoju.
Implementacja SLO polega w Dynatrace na przygotowaniu definicji w widoku konfiguracji. Przejdźmy ścieżkę takiej definicji. Z lewego menu odszukujemy „Service-level objectives”. Tam znajdziemy obecną listę SLO oraz przycisk „Add new SLO”.

Po jego kliknięciu możemy wybrać z predefiniowanych typów SLO.
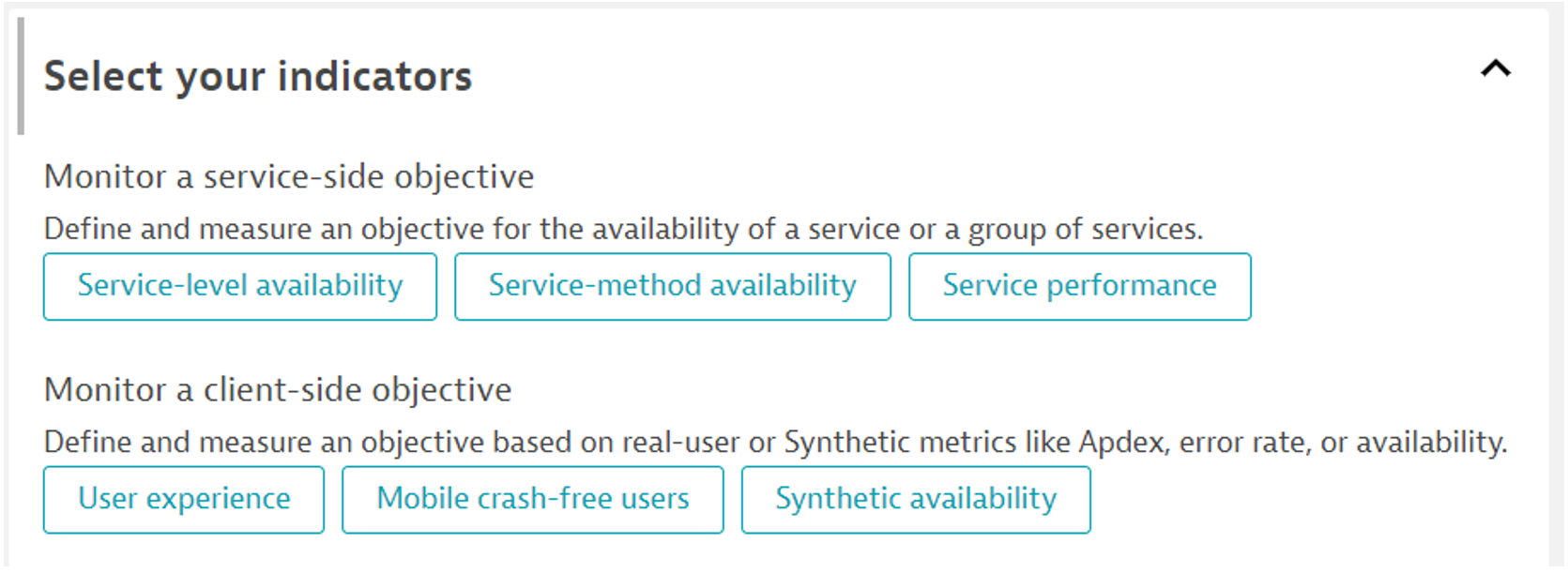
Definiujemy nazwę oraz weryfikujemy metrykę, według której liczona będzie wartość.
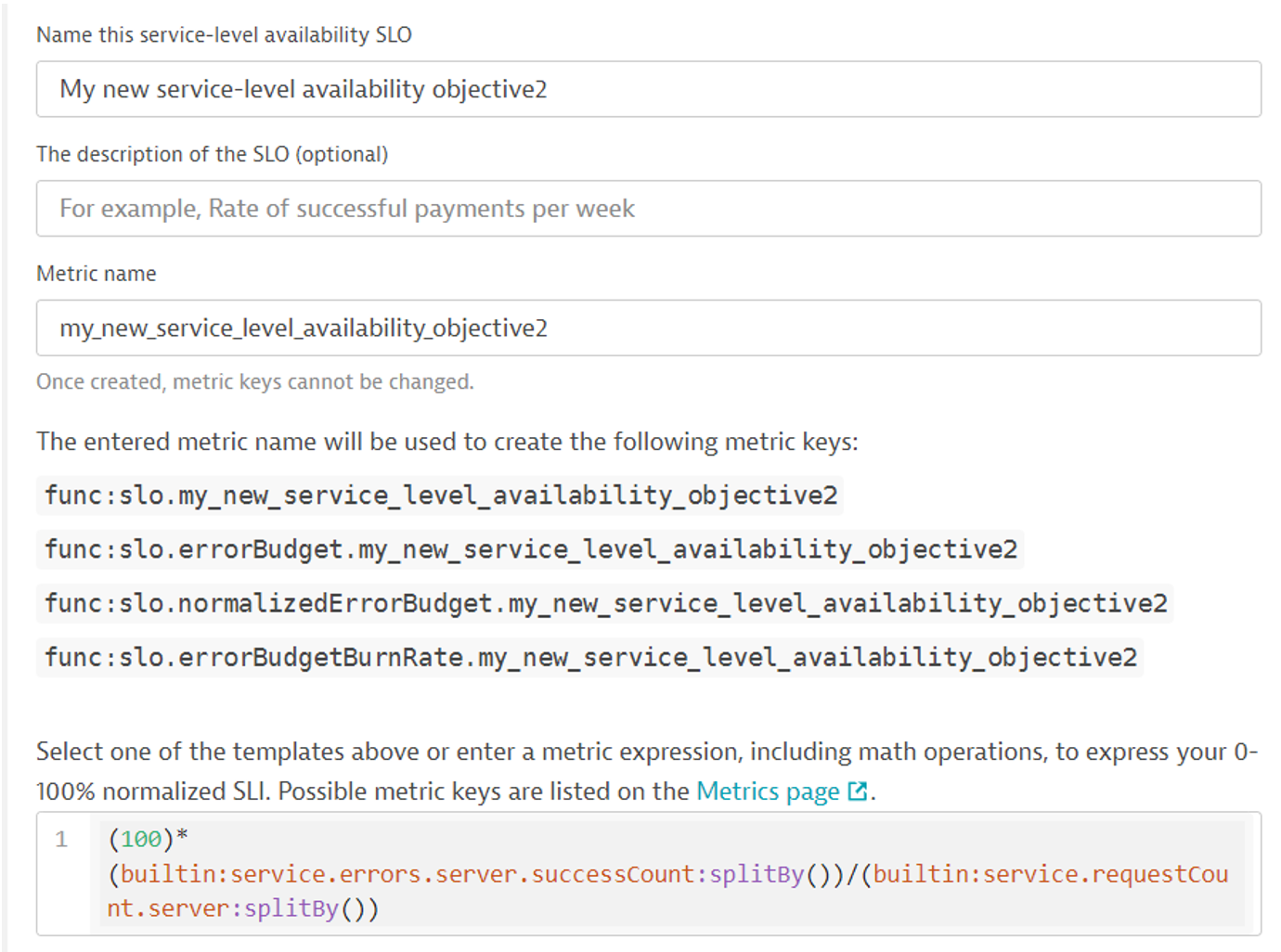
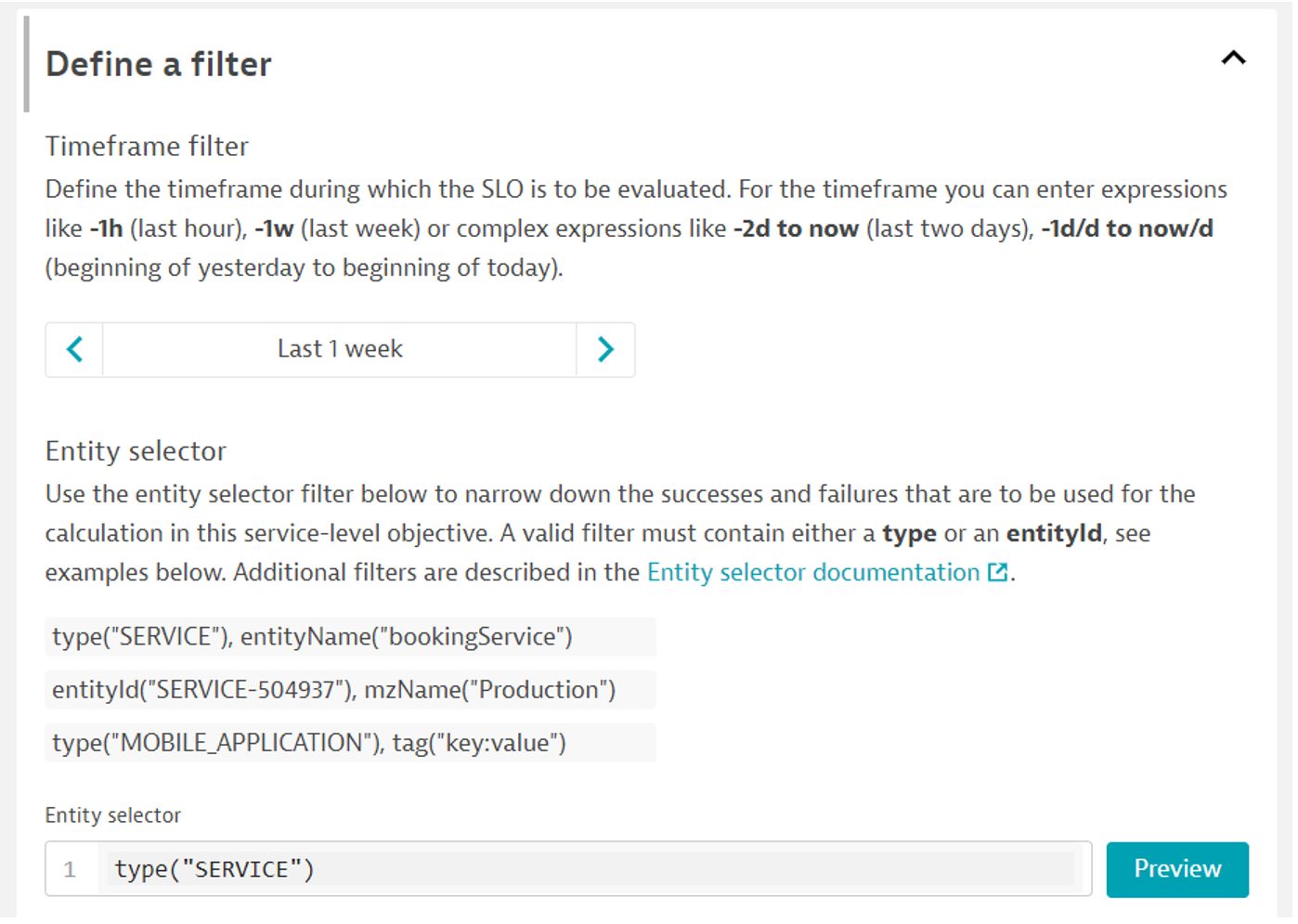
Kluczowe jest, aby wyrażenie metryczne przyjmowało wartości z zakresu od 0 do 100%. W zakładce „Define a filter” definiujemy zakres czasu oraz zakres elementów, z których liczone jest SLO.
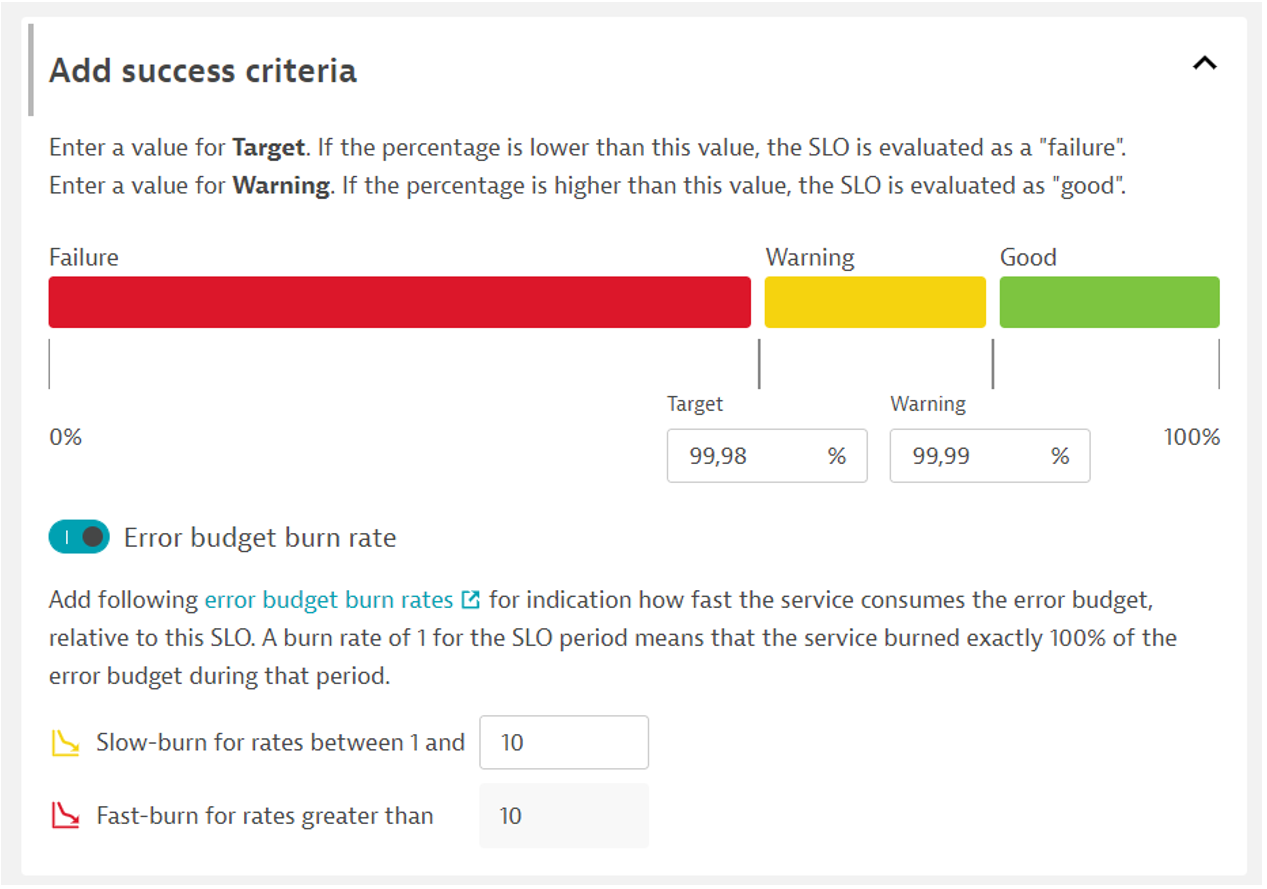
Na koniec w zakładce „Add success criteria” ustalamy cel SLO oraz określenie tempa spalania budżetu błędu. Może nas on ostrzec powiadomieniem, że przy obecnym tempie cel nie zostanie wypełniony.
Jak może wyglądać przykładowa definicja SLO dla poziomu zadowolenia użytkowników? Wybierając konkretną aplikację z zakładki „Frontend” możemy klikając na […] -> „Add SLO” przejść do predefiniowanej konfiguracji.
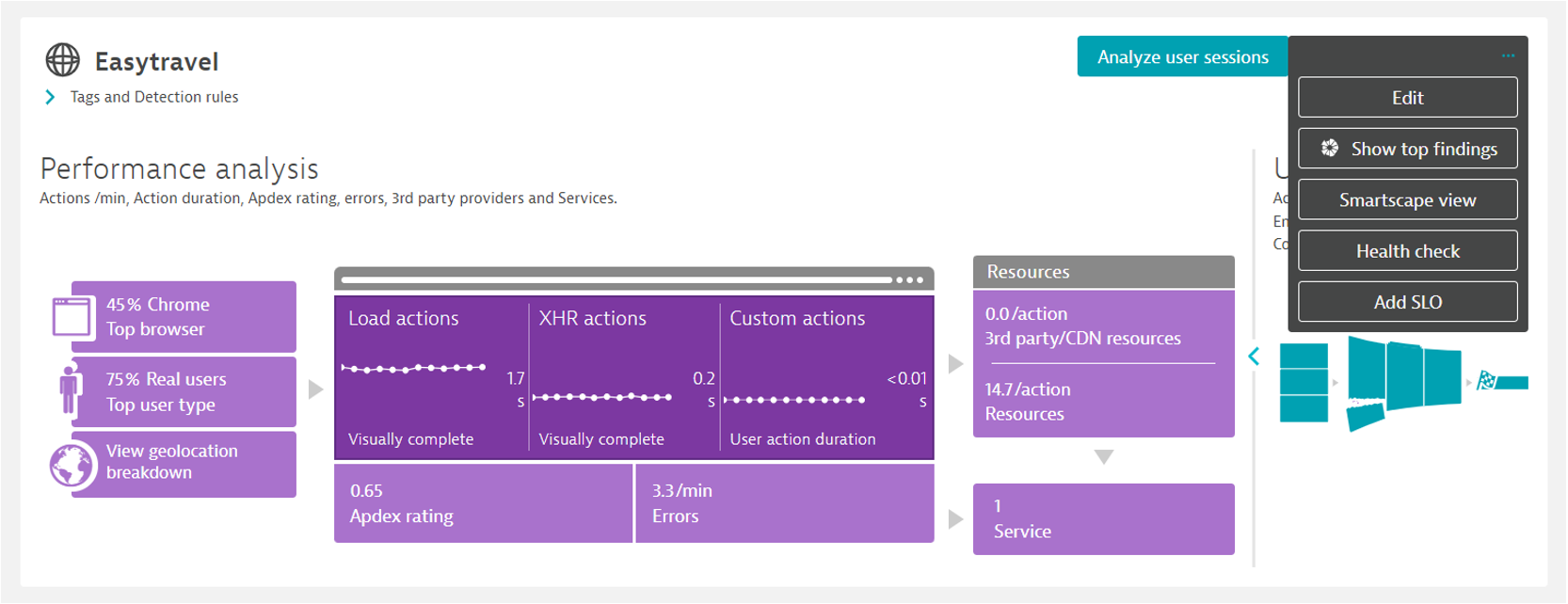
Poniżej zrzut ekranu przykładowego SLO opartego o poziom satysfakcji użytkowników według wskaźnika APDEX. Warto przed jej zatwierdzeniem kliknąć „Evaluate”, aby sprawdzić przeliczenie SLO z ostatniego zakresu czasu.
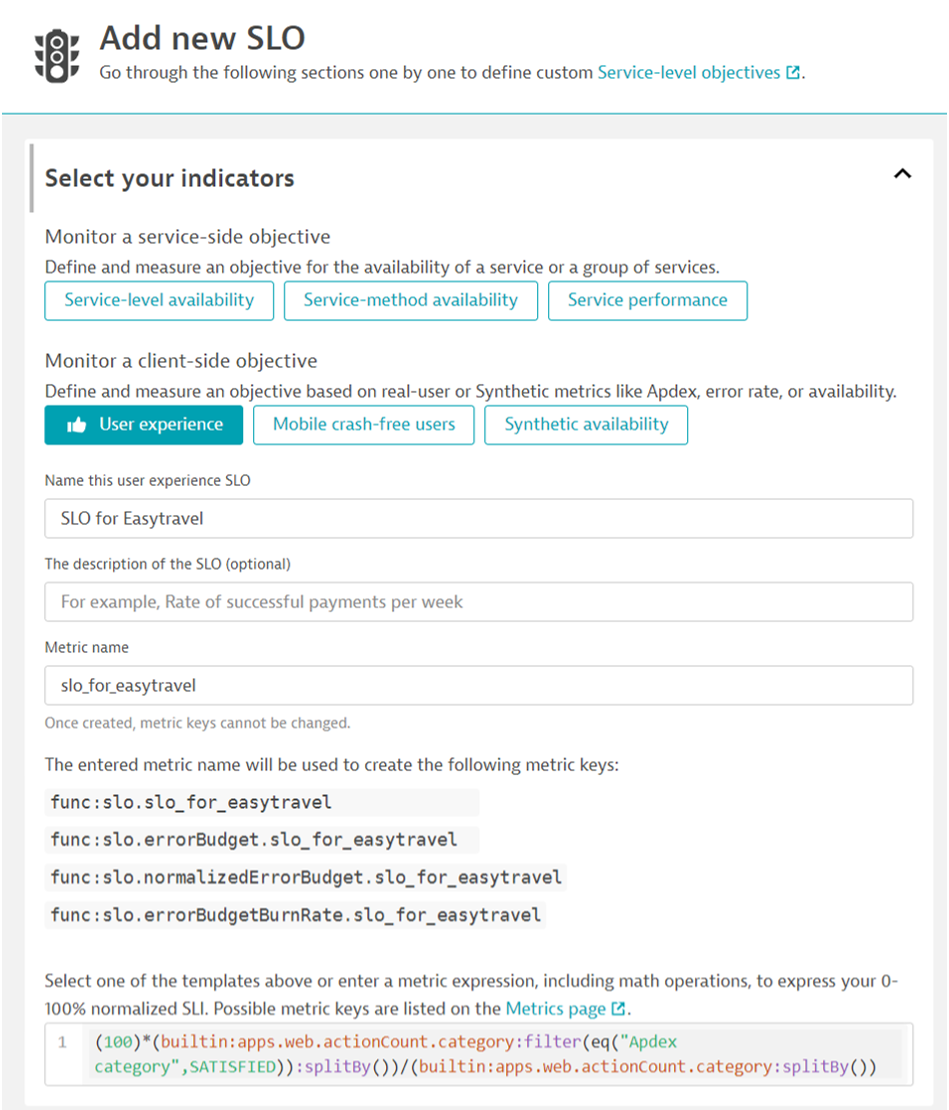
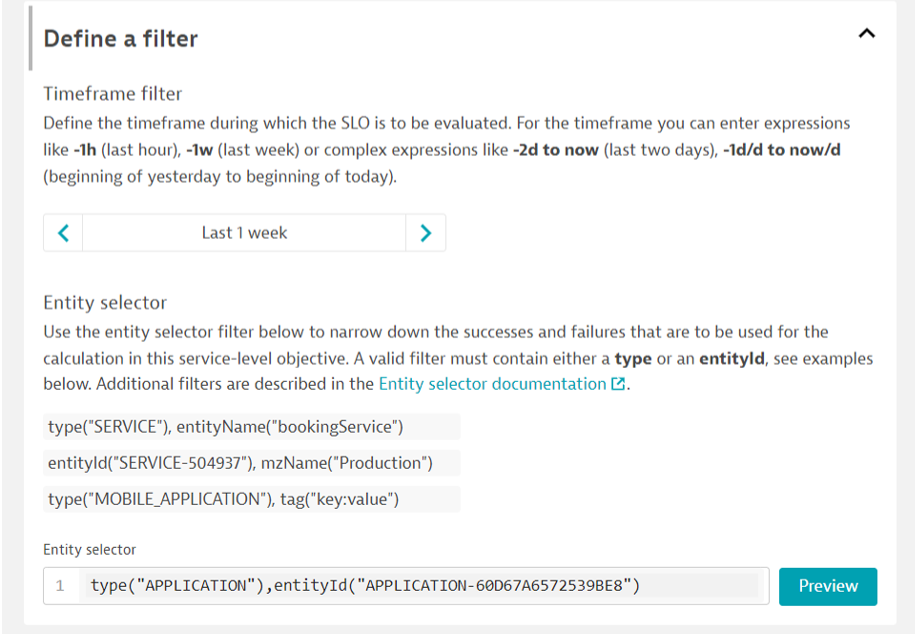
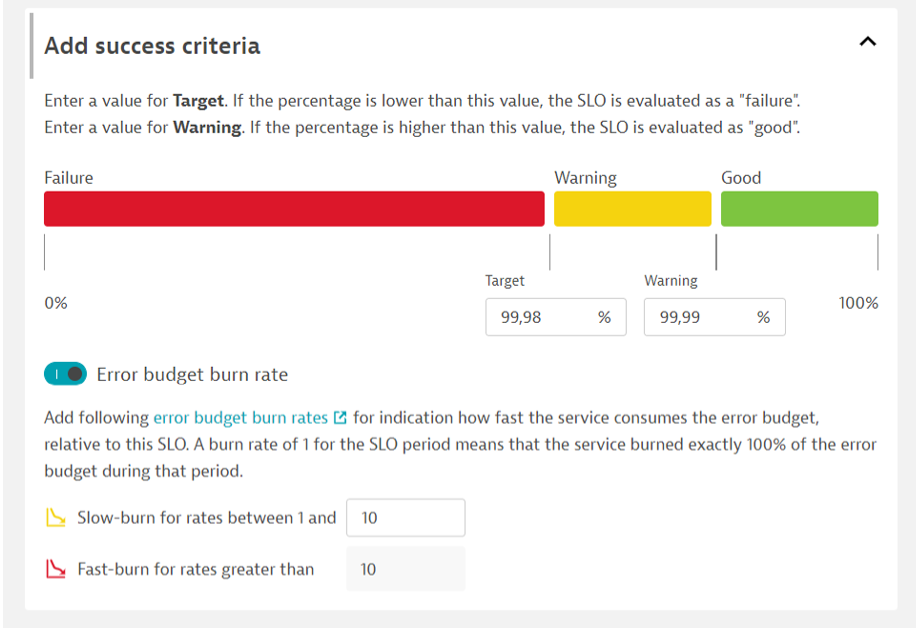

Kolejny przykład dla wydajności, czasów odpowiedzi jednej z kluczowych usług. Wystarczy wybrać z widoku usługi […] -> „Add SLO”.
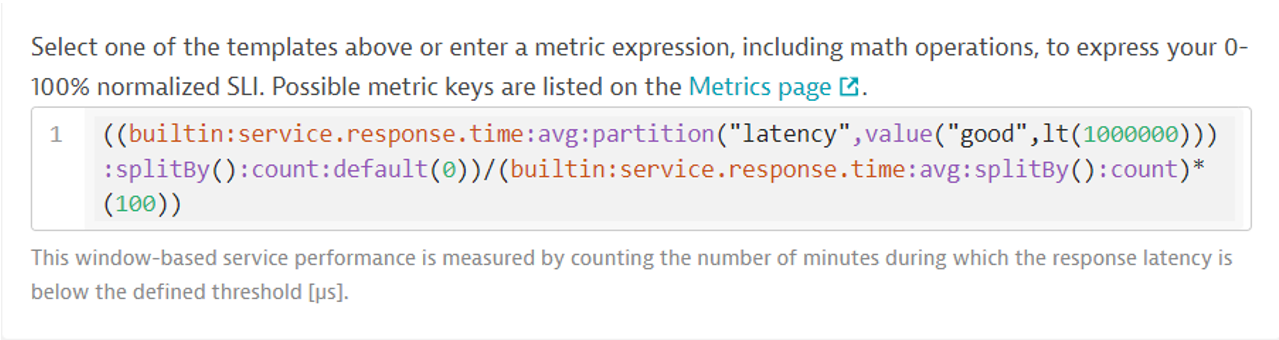
Kliknijmy w generatorze na „Service performance”. W polu z definicją metryki pojawi się metryka oparta o „service response time” z określeniem wartości „good” jako „lt”, czyli „less than”, oraz czas wyrażony w µs – na przykład 1 s = 1 000 000 µs. Liczymy stosunek ilości zapytań poniżej 1 s do łącznej liczby zapytań w danej jednostce czasu.
Innym przykładem może być zużycie procesora hostów, które w przykładzie ma wynosić poniżej 10%. Mierzymy w ten sposób czas w ciągu zakładanego ostatniej godziny, tygodnia czy miesiąca, w których to zużycie było w tym zakresie. Zgodność wyrażenia, które później wklejamy w definicji SLO możemy sprawdzić w widoku Data explorer, jak poniżej:

Dostępność aplikacji mierzona z zewnątrz również może być przeniesiona do SLO. Wykorzystamy do tego roboty syntetyczne wbudowane w Dynatrace (Synthetic Monitoring), które z różnych lokalizacji na świecie mogą weryfikować, czy nasza strona i konkretne jej funkcje są dostępne. Definiując SLO dla testu syntetycznego typu „Browser clickpath ” jako metrykę określamy:

Natomiast w „Entity selector” wybieramy odpowiedni test syntetyczny lub ich grupę, a w selektorze „type” wpisujemy „SYNTHETIC_TEST”:

Analogicznie w przypadku „HTTP monitor” wybieramy metrykę „builtin:synthetic.http.availability. location.total:splitBy()” a „type” to „HTTP_CHECK”.
Definicję SLO możemy oprzeć o dowolną metrykę dostępną w Dynatrace, którą znormalizujemy wyrażeniem do zakresu 0-100%. Warto pamiętać o wszelkich customowych metrykach, które wyznaczymy np. z Multidimensional analysis dla usług czy przez zapytanie USQL dla sesji użytkowników z Real User Monitoring. Oczywiście zawsze istnieje możliwość importu metryk zewnętrznych poprzez API Dynatrace’a lub rozszerzenia. Na koniec, SLO przypisane do danej aplikacji umieścimy na dashboardzie, który w jasny sposób wspólnie z innymi zero-jedynkowymi wskaźnikami zdrowia i kluczowymi metrykami pokazywać będzie stan naszej aplikacji.
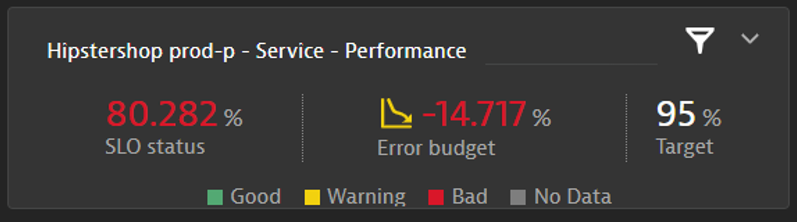
Podsumowując, poprzez określenie mierzalnych celów dostępności i wydajności dla naszych aplikacji wskazujemy skuteczność i jakość działań naszych i naszych poddostawców, dążąc do zapewnienia doskonałego doświadczenia użytkownikom. Poznaliśmy, jak Dynatrace realizuje ideę SRE i pozwala na definicję takich właśnie wskaźników w formie SLO. Rozumiemy, że kluczowe jest przede wszystkim zebranie wszystkich SLO w ramach jednej platformy dostępnej dla wszystkich w naszej organizacji, jak wspiera to transparentność i zrozumienie pomiędzy zespołami, również tymi spoza obszaru technologii. Na wspólnym spotkaniu możemy nie tylko sprawdzić, jak radzimy sobie w porównaniu z poprzednim tygodniem czy miesiącem, ale również zrozumieć dokładnie, dlaczego nie udało się osiągnąć zamierzonych celów przeglądając powiązane przez Dynatrace konkretne problemy, które doprowadziły do wyniku poniżej naszych oczekiwań. W trakcie ocenianego okresu znamy również tempo wypalania się naszego budżetu błędu (Error budget). Obserwując go czy nawet ustawiając powiadomienia ostrzegawcze będziemy świadomi, że możemy nie spełnić naszego celu przy obecnym trendzie. Świetnie realizuje to metodologię SRE – przejście na wyższy poziom rozumienia działania, dostępności naszych aplikacji i proaktywnego lokalizowania najważniejszych obszarów do poprawy.